
1.9 LAB – Query execution plans (Sakila)
This lab illustrates how minor changes in a query may have a significant impact on the execution plan.
MySQL Workbench exercise
Refer to the film, actor, and film_actor tables of the Sakila database. This exercise is based on the initial Sakila installation. If you have altered these tables or their data, your results may be different.
Do the following in MySQL Workbench:
- Enter the following statements:
USE sakila;
SELECT last_name, first_name, ROUND(AVG(length), 0) AS average
FROM actor
INNER JOIN film_actor ON film_actor.actor_id = actor.actor_id
INNER JOIN film ON film_actor.film_id = film.film_id
WHERE title = "ALONE TRIP"
GROUP BY last_name, first_name
ORDER BY average;
- Highlight the SELECT query.
- In the main menu, select Query > Explain Current Statement.
- In the Display Info box, highlighted in red below, select Data Read per Join.
Workbench displays the following execution plan:
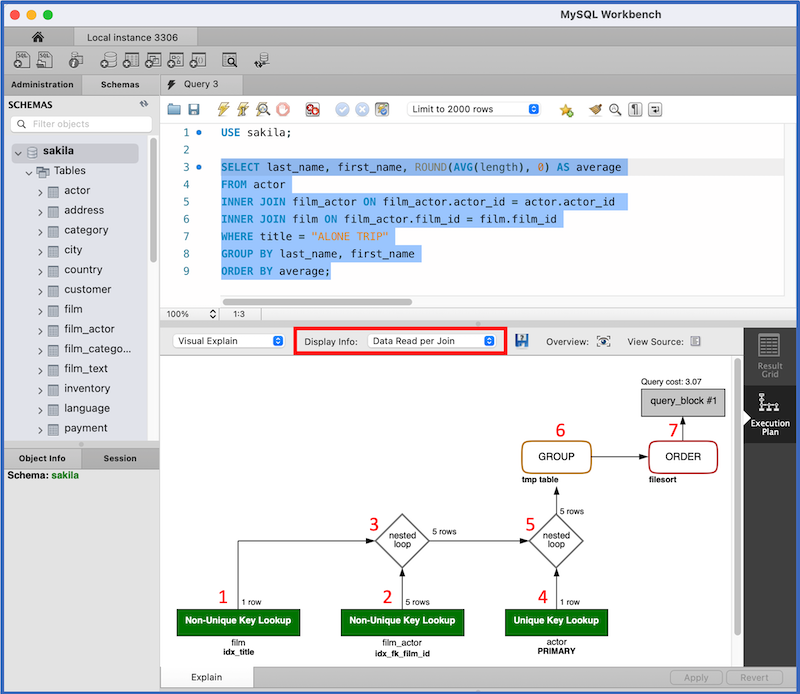
The execution plan depicts the result of EXPLAIN for the SELECT query. The execution plan has seven steps, corresponding to the red numbers on the screenshot:
- Access a single
filmrow using theidx_titleindex on thetitlecolumn. - Access matching
film_actorrows using theidx_fk_film_idindex on thefilm_idforeign key. - Join the results using the nested loop algorithm.
- Access
actorrows via the index on the primary key. - Join
actorrows with the prior join result using the nested loop algorithm. - Store the result in a temporary table and compute the aggregate function.
- Sort and generate the result table.
Refer to for an explanation of the nested loop algorithm.
Now, replace = in the WHERE clause with < and generate a new execution plan. Step 1 of the execution plan says Index Range Scan. The index scan accesses all films with titles preceding “ALONE TRIP”, rather than a single film.
Finally, replace < in the WHERE clause with > and generate a third execution plan. Step 1 of the execution plan says Full Table Scan and accesses actor rather than film.
zyLab coding
In the zyLab environment, write EXPLAIN statements for the three queries, in the order described above. Submit the EXPLAIN statements for testing.
The zyLab execution plans do not exactly match the Workbench execution plans, since this lab uses a subset of film, actor, and film_actor rows from the Sakila database.
NOTE: In submit-mode tests that generate multiple result tables, the results are merged. Although the tests run correctly, the results appear in one table.